
Locked Content
Un nuevo estudio pone en duda la capacidad de los últimos modelos de lenguaje, como GPT-4 y Gemini 1.5 Pro, de ser «multimodales» al no poder comprender imágenes y audio además de texto como se promocionan. De acuerdo con la investigación, es posible que estos modelos no logren interpretar la información visual de la manera esperada e incluso podrían no ser capaces de hacerlo en absoluto.
Es importante aclarar que no se han realizado afirmaciones del tipo «Esta inteligencia artificial puede percibir como lo hace la gente» (aunque quizás algunas personas lo hayan expresado así). No obstante, en el ámbito del marketing y la promoción de estos modelos, se emplean términos como «capacidades visuales» y «comprensión visual» para destacar sus funcionalidades. Se destaca la capacidad del modelo para visualizar y analizar imágenes y videos, lo que le permite abordar diversas tareas, desde resolver problemas académicos hasta realizar seguimientos deportivos en lugar del usuario.
A pesar de que las afirmaciones de estas empresas están cuidadosamente redactadas, es claro que buscan comunicar que el modelo tiene sentido en ciertos aspectos. El modelo lo logra al igual que en matemáticas o en la escritura de historias: al identificar patrones en los datos de entrada que coinciden con los patrones en los datos de entrenamiento. Esta similitud provoca que los modelos fallen de la misma manera que en otras tareas aparentemente simples, como seleccionar un número al azar.
Investigadores de la Universidad de Auburn y la Universidad de Alberta llevaron a cabo un estudio sistemático sobre la Comprensión visual de los modelos de Inteligencia Artificial (IA) actuales. En este estudio, se plantearon diversas tareas visuales simples a los modelos multimodales más grandes, como determinar si dos formas se superponen, contar la cantidad de pentágonos en una imagen o identificar qué letra de una palabra está encerrada en un círculo. Se puede acceder a un resumen del estudio en esta página.
Estas son tareas que un estudiante de primer grado podría realizar con facilidad, pero que representaron un desafío significativo para los modelos de Inteligencia Artificial.
El coautor Anh Nguyen expresó que las siete tareas asignadas son de naturaleza simple y podrían ser ejecutadas con un nivel de precisión del 100% por parte de los seres humanos. Sin embargo, se espera que las inteligencias artificiales logren realizarlas de la misma manera, lo cual no está ocurriendo en la actualidad. Nguyen enfatizó el hecho de que los modelos más avanzados continúan presentando fallos en dichas tareas.

Imagen: Rahmanzadehgervi y otros colaboradores.
La prueba de formas superpuestas fue realizada, la cual es considerada una tarea de razonamiento visual elemental. Durante el experimento, se observó que los modelos no lograron realizarla de manera consistente al presentarse dos círculos superpuestos con diferentes grados de proximidad. Por ejemplo, el modelo GPT-4o tuvo un rendimiento correcto superior al 95 % cuando los círculos estaban muy separados, pero solo acertó alrededor del 18 % de las veces cuando estaban cercanos o superpuestos. Por otro lado, el modelo Gemini Pro 1.5 obtuvo una calificación de 7 sobre 10 en distancias cortas, siendo considerado el mejor en esta tarea, aunque aún con margen de mejora.
Las ilustraciones no representan con precisión el desempeño de los modelos, sino que buscan evidenciar la variabilidad de los modelos en distintas situaciones. Las estadísticas específicas de cada modelo se detallan en el documento.
¿Qué le parece la posibilidad de cuantificar los círculos entrelazados en una imagen?
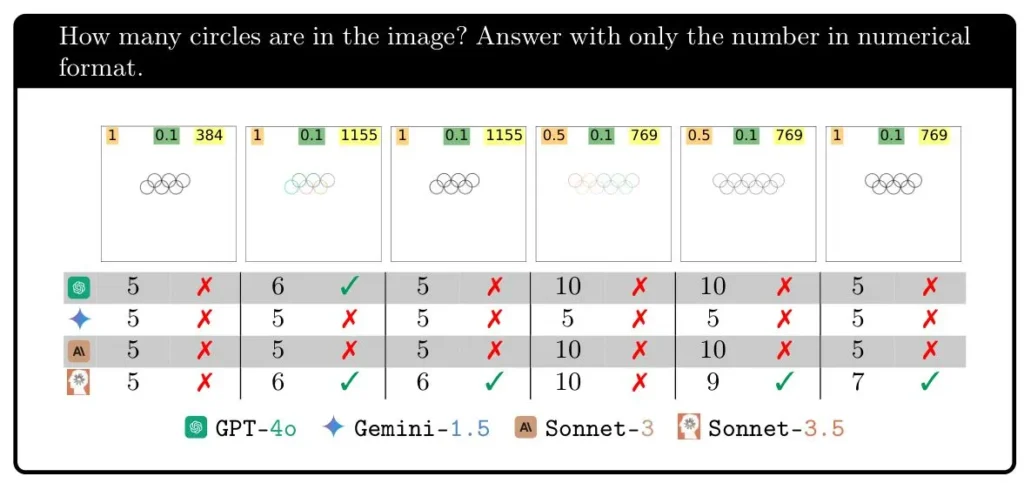
Imagen: Rahmanzadehgervi y otros colaboradores
La inteligencia artificial visual logra un 100 % de precisión al identificar cinco anillos, sin embargo, su desempeño se ve afectado negativamente al añadir un anillo adicional. En este escenario, Géminis no logra acertar ninguna vez, mientras que Sonnet-3.5 acierta un tercio de las veces y GPT-4o un poco menos de la mitad de las veces. La adición de un anillo adicional incrementa la complejidad de la tarea, aunque para ciertas personas, añadir uno más puede facilitarla.
El propósito de este experimento es demostrar que los modelos no reflejan con precisión nuestra percepción visual. Aunque los modelos puedan tener deficiencias en su visión, no se esperaría que las imágenes con 6, 7, 8 y 9 anillos tuvieran resultados tan inconsistentes.
Las demás tareas evaluadas exhibieron patrones análogos, no se debía a una cuestión de percepción o razonamiento correcto o incorrecto, sino que aparentemente existía algún otro motivo por el cual podían realizar el conteo en un escenario pero no en otro.
Una posible respuesta a esta cuestión evidente es la siguiente: ¿Cuál es la razón por la que los modelos son tan precisos al identificar correctamente 5 círculos, pero fracasan notablemente en otros casos, como al reconocer 5 pentágonos? Es importante destacar que el modelo Sonnet-3.5 tuvo un desempeño bastante acertado en este último caso. La razón de esta disparidad radica en que todos los modelos han sido entrenados con una imagen específica que destaca la presencia de 5 círculos: los Anillos Olímpicos.

Imagen: COI
El logotipo se encuentra repetidamente en los datos de entrenamiento y se detalla en el texto alternativo, las pautas de uso y los artículos relacionados. Sin embargo, la presencia de 6 anillos entrelazados o 7 en los datos de entrenamiento es inexistente. La falta de comprensión visual sobre los anillos, superposiciones y otros conceptos es evidente en este contexto.
Consulté a los investigadores sobre su opinión respecto a la falta de capacidad que se les atribuye a los modelos. Al igual que otros términos empleados, posee una connotación antropomórfica que no es completamente precisa, pero resulta complicado evitar su uso.
Nguyen señaló la diversidad de significados que puede tener el término «ciego», tanto en referencia a los seres humanos como a las inteligencias artificiales. Destacó la falta de un vocablo específico para describir la incapacidad de las IA para interpretar las imágenes que se les presentan. Asimismo, resaltó la ausencia de tecnología actual que permita visualizar con precisión la percepción visual de un modelo, cuyo comportamiento resulta de una compleja interacción entre el texto de entrada, la imagen de entrada y múltiples parámetros.
Se ha sugerido que los modelos no poseen una percepción visual exacta, sino que su interpretación de la información visual de una imagen es aproximada y abstracta, como por ejemplo identificar la presencia de un círculo en el lado izquierdo. Estos modelos carecen de la capacidad de realizar juicios visuales, por lo que sus respuestas se asemejan a las de alguien que posee conocimiento sobre una imagen, pero no puede visualizarla realmente.
Como último ejemplo, Nguyen presentó un caso que respalda la hipótesis previamente planteada.

Imagen: Anh Nguhen
Al superponerse un círculo azul y un círculo verde, se genera comúnmente un área sombreada en cian, similar a un diagrama de Venn. La respuesta a esta situación es predecible para cualquier individuo con conocimientos en la materia. Sin embargo, la percepción de la situación puede variar si se consideran diferentes enfoques o perspectivas.
¿Implica esto que los modelos de IA «visuales» carecen de utilidad? Lejos de ser así. La incapacidad de realizar razonamientos básicos sobre ciertas imágenes revela limitaciones fundamentales, pero no específicas, en sus capacidades. Es probable que cada uno de estos modelos sea altamente preciso en áreas como la interpretación de acciones y expresiones humanas, fotografías de objetos y situaciones cotidianas, entre otros. De hecho, estas son las tareas que se espera que puedan interpretar.
Las empresas de inteligencia artificial promocionan sus modelos con una imagen idealizada de sus capacidades, sugiriendo una precisión infalible en tareas como la detección de actividades humanas. Sin embargo, investigaciones como la presente revelan que esta precisión no implica una comprensión visual convencional por parte de los modelos.

 y selecciona
y selecciona {kind=link}