
Locked Content
Desde su lanzamiento en 2017, ClickUp se ha convertido en una herramienta de productividad popular y bien financiada. Y como todas las herramientas de productividad, el equipo de ClickUp también ha escuchado el canto de sirena de la inteligencia artificial. La compañía ha lanzado lo que llama «ClickUp Knowledge Management», que combina un nuevo editor similar a un wiki y un nuevo sistema de inteligencia artificial que también puede incorporar datos de Google Drive, Dropbox, Confluence, Figma y otras fuentes. La compañía apunta a construir una herramienta que pueda rivalizar con otros servicios populares como Notion y Atlassian’s Confluence.
El cofundador y director ejecutivo de ClickUp, Zeb Evans, cree que la IA es fundamental para la gestión del conocimiento, pero para aprovecharla al máximo, las empresas necesitan una fuente centralizada para todo ese conocimiento.
“En la mayoría de las empresas, tienes tu conocimiento real, que está escrito en un lugar determinado, como en Confluence [wiki] o Notion”, dijo. “Y luego tienes mucho conocimiento en diferentes lugares. Hay algunas nuevas empresas como Glean que están empezando a conectar los puntos entre ellos, pero el verdadero problema que existe ahora es que puedes ir a una herramienta y conectar los puntos, pero en realidad no puedes editar y administrar esos puntos y hacer el trabajo sobre el trabajo en esa misma plataforma”.
Ese es un problema al que el propio equipo de ClickUp se enfrentó a lo largo de los años. Y aunque ya se podían crear documentos en la plataforma, el equipo decidió crear un nuevo producto desde cero que comienza con una wiki en su núcleo (y que se parece más a Notion que a Confluence), pero que luego también se integra con una nueva IA, un sistema que puede extraer datos de todas estas otras fuentes.
“Pueden crearse wikis en ClickUp, pero ahora también nos conectamos con todas las otras herramientas de trabajo y agregamos el conocimiento en un cerebro central de la empresa, por así decirlo, donde se pueden escribir wikis basadas en todo el contexto que está disponible. ”, agregó Evans.
El resultado, sostiene ClickUp, es un sistema que reúne lo mejor de Notion, Confluence y Glean para permitir a los usuarios crear documentos rápidamente. Para textos como informes de proyectos, actualizaciones del equipo, resúmenes y presentaciones, el equipo ya creó plantillas prediseñadas. Los usuarios también pueden utilizar el sistema para asignar tareas automáticamente, completar datos de tareas y encontrar tareas duplicadas.
Por supuesto, también existe un chatbot que las personas pueden utilizar para consultar sus documentos. Lo interesante aquí, sin embargo, es que ClickUp ha construido el sistema de una manera que no sólo cita todas sus fuentes sino que también pregunta proactivamente al usuario si debe crear documentos relevantes para ellos en función de los resultados de la consulta.
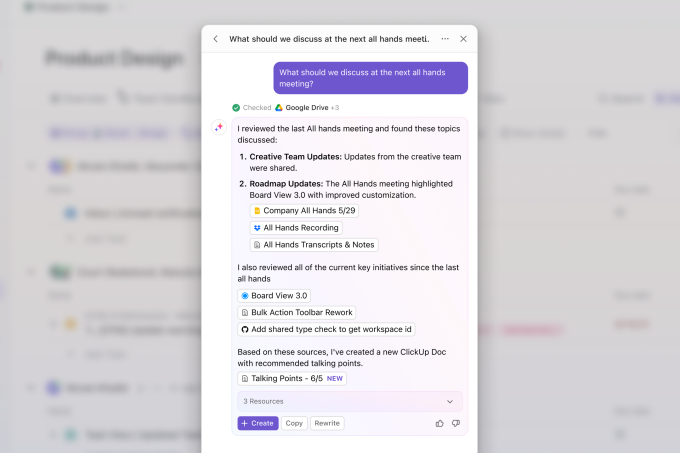
Evans enfatizó que el sistema tiene en cuenta los permisos de acceso existentes de un empleado, por lo que la IA solo mostrará información con la que un usuario determinado puede trabajar.
Hace unos dos años, ClickUp adquirió Slapdash, una herramienta de búsqueda universal que reunió datos de lo que tradicionalmente son aplicaciones SaaS aisladas. Desde entonces, ClickUp trabajó en la reconstrucción de la arquitectura Slapdash para que pudiera funcionar con IA. Esto ahora permite que ClickUp Knowledge Management realice recuperación de generación aumentada (RAG), que rápidamente se ha convertido en el estándar de la industria para aumentar modelos de lenguaje grandes (LLM) con información adicional y actualizada.
La generación mejorada por recuperación (RAG, Retrieval-Augmented Generation) es el proceso de optimización de la salida de un modelo lingüístico de gran tamaño, de modo que haga referencia a una base de conocimientos autorizada fuera de los orígenes de datos de entrenamiento antes de generar una respuesta. Los modelos de lenguaje de gran tamaño (LLM) se entrenan con grandes volúmenes de datos y usan miles de millones de parámetros para generar resultados originales en tareas como responder preguntas, traducir idiomas y completar frases. RAG extiende las ya poderosas capacidades de los LLM a dominios específicos o a la base de conocimientos interna de una organización, todo ello sin la necesidad de volver a entrenar el modelo. Se trata de un método rentable para mejorar los resultados de los LLM de modo que sigan siendo relevantes, precisos y útiles en diversos contextos.
“No es una integración a nivel de superficie, donde con muchas de estas cosas, usan una API para buscar todas las cosas. En cambio, en realidad estamos digiriendo todas sus bases de datos de sus aplicaciones conectadas para que podamos hacer muchas cosas interesantes con eso”, dijo Evans.
De cara al futuro, ClickUp pretende utilizar este nuevo sistema para reducir aún más la cantidad de horas relacionado con el trabajo mecánico.
“Nuestro gran objetivo para este próximo lanzamiento es acabar con el trabajo por el trabajo. Odio el trabajo sobre el trabajo. Odio tener que hacer un montón de preguntas y descubrir dónde están las cosas y en qué está trabajando la gente. En todas las empresas, si se calcula cuánto tiempo que se dedica a escribir una agrupación de tareas o resumen todos los días es elevado: ‘Esto es lo que hice hoy. Esto es lo que hice ayer.’ Es una locura”, dijo Evans.

 y selecciona
y selecciona {kind=link}